Signing Is Not Enough: Why AI Artifact Provenance Needs to Be a Graph

You have a fine-tuned model in production. It has a valid signature. It passed a security scan. Your audit trail shows clean attestations. Can you prove what it was built from?
Signing tells you an artifact hasn’t been tampered with since it was signed. It tells you nothing about what went into creating it.
What signing actually gives you
OCI attestations solve a real problem. You can sign a ModelKit, attach scan results as attestations, and verify that the artifact in your registry is the same one that passed your security checks. Tools like Jozu Hub automate this: when you import a model or run a security scan, the scan result is a signed attestation attached directly to the artifact. No manual steps, no separate metadata store.
This is valuable. It’s also insufficient.
Single-artifact verification answers one question: is this artifact what it claims to be? It doesn’t answer: what went into producing it?
The fine-tuning problem
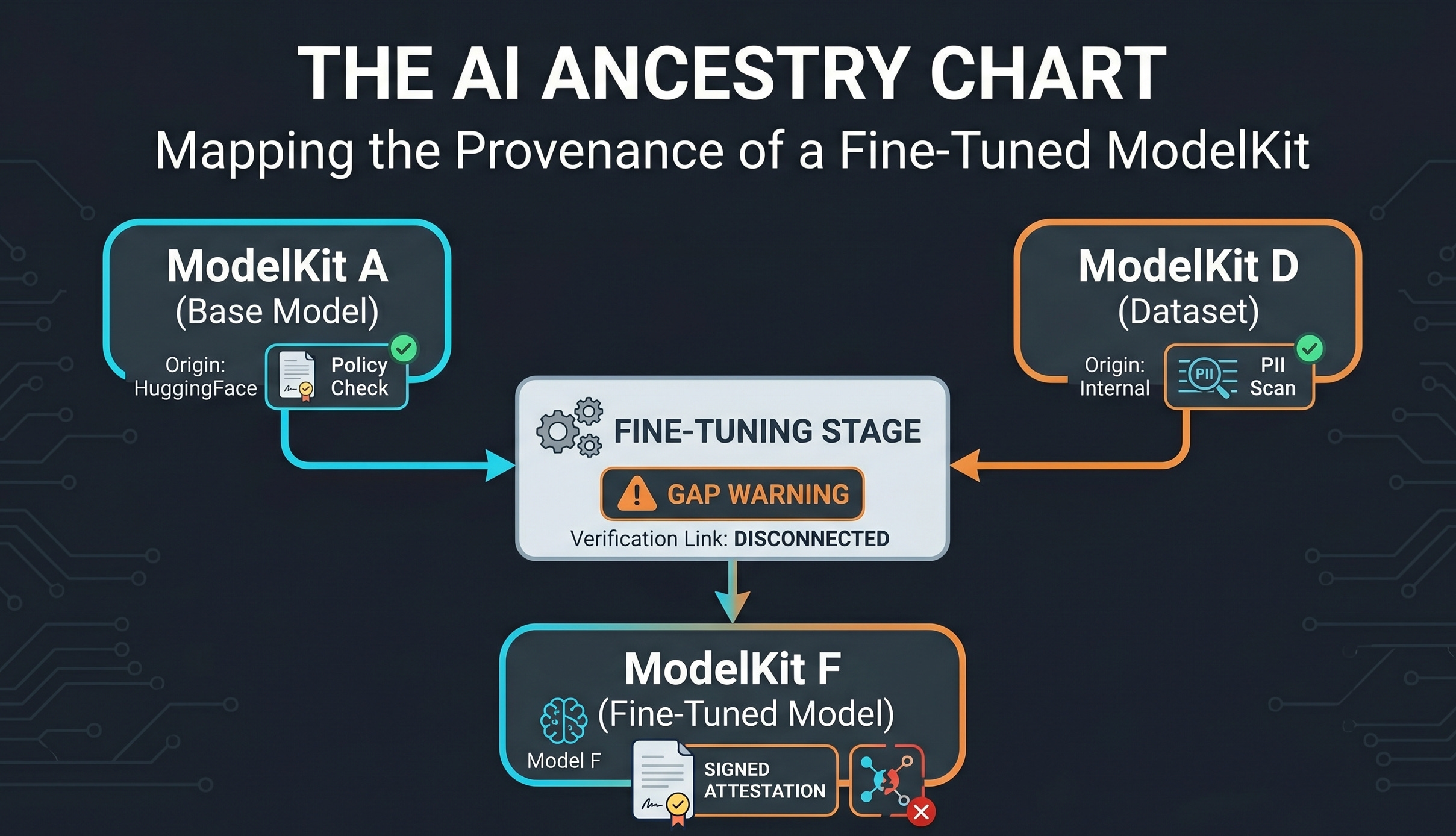
Consider three ModelKits in your registry:
ModelKit A: Base model (
registry.example.com/models/llama-base:v2), imported from HuggingFace. Jozu Hub has attached an import attestation recording its origin and a security scan attestation confirming the state of threat vectors.ModelKit D: Dataset (
registry.example.com/datasets/customer-support:v1), curated internally. Jozu Hub attaches a security scan attestation including PII scores.ModelKit F: Fine-tuned model (
registry.example.com/models/finetuned-support:v1), produced by fine-tuning A on D.
F has its own attestations. It was signed. It was scanned. But none of A’s provenance flows to F. None of D’s provenance flows to F. You can verify F in isolation and have no idea whether the base model was vetted or the dataset was scanned.
This is the gap.
Chains vs. graphs
Single-artifact provenance chaining is a known problem. Each attestation on an artifact can reference previous attestations, creating a linear history: built, then scanned, then approved. Tools exist for this. SLSA and in-toto define the formats. Rekor provides an append-only transparency log for ordering.
But fine-tuning isn’t a linear chain. F is produced from two inputs. Each input has its own attestation chain. The provenance structure is a graph, not a line.
F’s attestations need to explicitly capture its inputs — by digest — so that verification can walk the graph: confirm F, then confirm each input has its own valid chain. Without that link, the input attestations exist but are disconnected from the output. They’re metadata on separate artifacts that happen to be in the same registry.
Wait.. what about SBOMs?
If you’re thinking your SBOM already captures this relationship, you’re half right. An SPDX 3 SBOM on F can list A and D as inputs using relationship types like TRAINED_ON and GENERATED_FROM. It records versions and describes the dependency structure. That’s lineage — and it belongs in the SBOM. Jozu Hub can generate these. The composition is documented.
But the SBOM is a manifest, not a verification record. It describes what went into F. It doesn’t prove that the build process actually consumed those specific artifacts, and it doesn’t capture whether each input met its policy requirements at the time it was consumed. A signed SLSA provenance attestation does — it’s a cryptographic assertion from the build pipeline that says “I consumed these artifacts, at these digests, at this time.”
SBOMs own lineage. Attestations own proof. The SBOM tells a policy engine which inputs to check. The attestation on each input is what it verifies. But that verification — walking the graph and confirming each input met its requirements — is the piece that doesn’t exist yet.
Capturing input provenance at build time
This is the step most pipelines skip. When the fine-tuning job runs and F is packaged, the build process must record which artifacts were consumed, pinned by digest.
Fine-tuning is a build. The same SLSA provenance format works here. The buildType identifies it as fine-tuning, and resolvedDependencies captures every input artifact by digest.
Retrieve the digests before fine-tuning starts:
DIGEST_A=$(crane digest registry.example.com/models/llama-base:v2)
DIGEST_D=$(crane digest registry.example.com/datasets/customer-support:v1)Then construct F’s provenance attestation:
{
"buildDefinition": {
"buildType": "https://jozu.dev/kitops/fine-tune/v1",
"externalParameters": {
"config": {
"learning_rate": 2e-5,
"epochs": 3,
"batch_size": 16
}
},
"resolvedDependencies": [
{
"uri": "registry.example.com/models/llama-base:v2",
"digest": { "sha256": "abc123..." },
"name": "base-model"
},
{
"uri": "registry.example.com/datasets/customer-support:v1",
"digest": { "sha256": "def456..." },
"name": "dataset"
}
]
},
"runDetails": {
"builder": {
"id": "https://jozu.dev/kitops/cli",
"version": { "kit": "0.9.2" }
},
"metadata": {
"invocationId": "ft-run-a7b8c9d0",
"startedOn": "2025-03-15T09:00:00Z",
"finishedOn": "2025-03-15T10:00:00Z"
}
}
}Attach it to F:
cosign attest --key cosign.key \
--predicate build-attestation.json \
--type https://slsa.dev/provenance/v1 \
registry.example.com/models/finetuned-support:v1Now F’s attestation explicitly names its inputs using the same standard that import provenance already uses. No new predicate type. No custom schema. The graph exists. But verification is still on you.
Where cosign’s scope ends
Cosign verifies individual attestations. It confirms that a specific attestation is validly signed and attached to a specific artifact. It does not traverse the graph.
Graph verification requires additional logic:
Retrieve F’s provenance attestation and extract the resolved dependencies
For each dependency, resolve the digest in the registry and pull its attestations
Verify each attestation’s signature
Confirm the required attestation types are present — A needs both an import provenance and a scan attestation, D needs a scan attestation
Recurse if any input was itself produced from further inputs
No off-the-shelf tool does this today. The primitives are all there — cosign for signature verification, crane for digest resolution, OCI registries for attestation storage. The orchestration that ties them into recursive graph traversal is not.
Why almost nobody is doing this
Cosign doesn’t do it. The OCI spec doesn’t require it. Most pipelines treat each artifact in isolation — sign it, scan it, ship it.
The infrastructure to capture and verify input provenance has to be built deliberately. There’s no off-the-shelf tool that takes a fine-tuned model and walks back through its inputs to confirm each one was properly vetted. The primitives exist — digests, attestations, registries — but the orchestration layer doesn’t.
Part of the reason is that most supply chain security content stops at “sign your artifacts.” That’s Step 1. The harder problem — proving that the signed artifact was built from verified inputs — doesn’t have a standard solution yet.
What this prevents
Without input provenance capture, an attacker or a careless pipeline can substitute a different dataset or base model between approval and fine-tuning. F’s own attestations pass verification. The substitution is invisible.
With the graph in place, any substitution breaks verification. The digest recorded in F’s build attestation won’t match the artifact in the registry, or the artifact at that digest won’t have the required attestations. Either way, verification fails. That’s the point.
Signing is necessary. The graph is what makes it sufficient.
The provenance infrastructure described here is part of what we’re building into KitOps and Jozu Hub. ModelKits already carry the attestations. The next step is making input provenance capture and graph verification part of the pipeline, not an afterthought. If you’re working through similar problems, Yoi canfind me on LinkedIn.